
June 8, 2025
Stanford Medicine’s recent announcement of ChatEHR—a new large language model (LLM) interface embedded directly into the Epic electronic health record (EHR)—has drawn substantial attention from across the medical and health tech community. The initiative, currently in pilot phase, aims to relieve clinicians from one of the most pressing burdens of modern care: inefficient and time-consuming navigation of the electronic medical record.
In this post, we summarize Stanford’s announcement and provide an analysis of professional sentiment from over 120 public LinkedIn comments, many from practicing clinicians and digital health leaders. Their reactions offer key insights into the expectations, enthusiasm, and caution surrounding AI in clinical workflows.
What is ChatEHR?
Stanford’s ChatEHR is designed to serve as a conversational interface within Epic that enables clinicians to interact with patient data using natural language. The system can answer queries like “Summarize this patient’s last hospitalization” or “List current medications and allergies,” drawing context-aware responses directly from the patient’s chart.
Unlike clinical decision support tools, ChatEHR does not give medical advice or diagnoses. It is focused on data retrieval and summarization, making it easier for physicians, nurses, and advanced practice providers to access relevant information without needing to navigate multiple EHR tabs.
The tool is built with privacy and safety in mind—data is processed entirely within the Epic environment. Stanford researchers are evaluating the tool using MedHELM, a clinical benchmark that builds on the HELM suite of large language model (LLM) tasks, but focused on real-world clinical applications such as note summarization, patient education, and administrative decision support.
Currently, 33 clinicians are piloting ChatEHR across emergency medicine, inpatient care, and administrative workflows.
Physician Sentiment: What LinkedIn Reveals
We analyzed 123 public LinkedIn comments on a popular post about the ChatEHR announcement. These comments offer a real-time snapshot of how health professionals view the integration of LLMs into clinical practice.
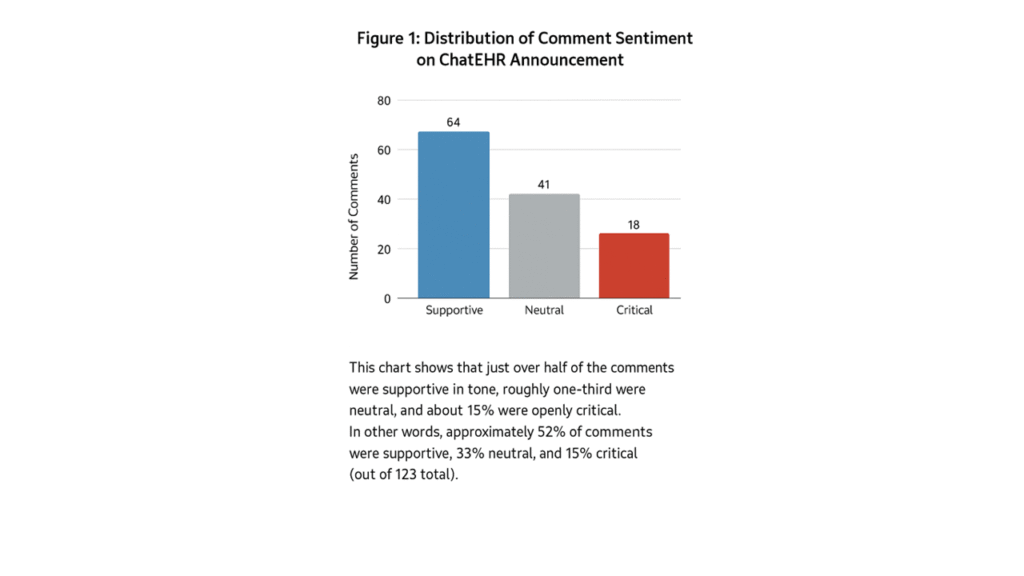
Overall Sentiment Distribution
As shown in Figure 1, sentiment toward ChatEHR is mostly positive:
- 52% of comments were supportive, praising the tool’s potential to improve efficiency and reduce EHR friction.
- 33% were neutral, often asking technical or implementation-related questions.
- 15% were critical, expressing concerns about AI reliability, privacy, and clinical appropriateness.
Sentiment by Professional Background
A breakdown of sentiment by profession reveals distinct perspectives:
| Profession | Supportive | Neutral | Critical | Total |
|---|---|---|---|---|
| Physicians (MD/DO) | 14 | 8 | 8 | 30 |
| Technologists/Entrepreneurs | 28 | 16 | 5 | 49 |
| Healthcare Administrators | 7 | 7 | 3 | 17 |
| Nurses/Allied Health | 3 | 2 | 0 | 5 |
| Researchers/Academics | 4 | 0 | 0 | 4 |
| Other/Unknown | 8 | 7 | 3 | 18 |
Key takeaways:
- Technologists and entrepreneurs were the most supportive, often highlighting innovation and feasibility.
- Physicians were more mixed—supportive of efficiency gains but wary of accuracy and regulatory gaps.
- Nurses and academics were generally supportive but underrepresented.
- Administrators maintained a balanced tone, often emphasizing operational alignment.
Major Themes Raised by Clinicians
From thematic analysis, the following recurring concerns and endorsements emerged:
1. Efficiency and Workflow Support
Many clinicians embraced ChatEHR’s potential to reduce “click fatigue.” Comments lauded its ability to rapidly summarize labs, medications, or hospitalization history, potentially saving several minutes per patient encounter.
“Finally, a tool focused on clinicians’ real pain—finding information, not giving advice.”
2. Integration Over Innovation
The tool’s seamless embedding in Epic was frequently praised. Several clinicians emphasized that for AI to be truly useful, it must be integrated into clinical workflow, not added as a separate tool.
“This only works if it’s part of the workflow—ideally baked into our Epic instance without more logins or clicks.”
3. Accuracy and Trustworthiness
Skeptical voices pointed out that large language models are prone to hallucinations, and over-trusting AI outputs in high-stakes settings could be dangerous.
“LLMs are confident and wrong. That’s worse than being unclear.”
Some also noted that clinicians may skip verification under pressure, underscoring the need for output traceability and source transparency.
4. Model Training and Bias
Professionals questioned how ChatEHR was trained, whether it was fine-tuned on clinical data, and whether it risks amplifying existing biases in patient records.
“Was this model retrained on patient data? If not, the whole thing is potentially unreliable.”
5. Privacy and Security
Though fewer in number, some commenters raised alarms about HIPAA compliance and data protection.
“Is this fully contained inside Epic? If not, we’re opening up serious risk.”
6. Regulatory Oversight and Evaluation
A small but vocal group questioned whether ChatEHR should be subject to FDA evaluation, given its proximity to clinical decision-making—even if it stops short of giving recommendations.
“Surprised this doesn’t require a clinical trial. What’s the regulatory pathway here?”
Stanford’s Response: Cautious, Transparent Rollout
Importantly, Stanford has anticipated many of these concerns. The rollout includes:
- Evaluation using MedHELM, a transparent benchmarking framework.
- Ongoing testing across real workflows (e.g., post-discharge, hospice eligibility).
- A firm boundary around no diagnostic or treatment functions.
- Plans to implement citation-backed outputs in the near future to improve trust and verifiability.
The tone of the announcement suggests that Stanford is prioritizing safety, usability, and clinician trust—a stance welcomed by many frontline providers.
Conclusion: Promising Direction, With Guardrails Needed
ChatEHR signals a shift in how health systems approach clinical AI—not as a separate tool, but as a native part of the clinician’s digital environment. The overwhelmingly supportive response from technologists and a cautiously optimistic reception among physicians suggest there is real appetite for this type of innovation.
That said, meaningful adoption will hinge on the technology’s fidelity, explainability, and integration. Future iterations must address trust, privacy, and governance if ChatEHR and similar systems are to scale safely.
As Stanford continues its pilot, the broader community will be watching closely—not just for performance metrics, but for answers to the fundamental question clinicians are asking: Can this actually help me care better for my patients?
Sources:
- Stanford Medicine News Center. “Stanford pilots ChatEHR”, June 2025.
- LinkedIn commentary on Joshua Liu’s June 2025 post (123 comments analyzed).